Garmin Connect code exploration
I’m a big fan of fitness tech, and one of my favourite devices is my Garmin fēnix-series sports watch. Garmin’s Connect platform lets you examine your data and activities, but there’s no public API for us to interact with programmatically. Consequently, it’s a perfect opportunity for me to look at it and see what I can pull out.
Garmin Connect
Garmin Connect is the companion app and website for Garmin devices that lets you see your activities, step counts and sleep data, compare your performance with your friends, track races and workout plans, and a whole host of other features. It’s the gateway between a user and their data — if you want to see anything recorded by a Garmin device, you need to go through Connect1.
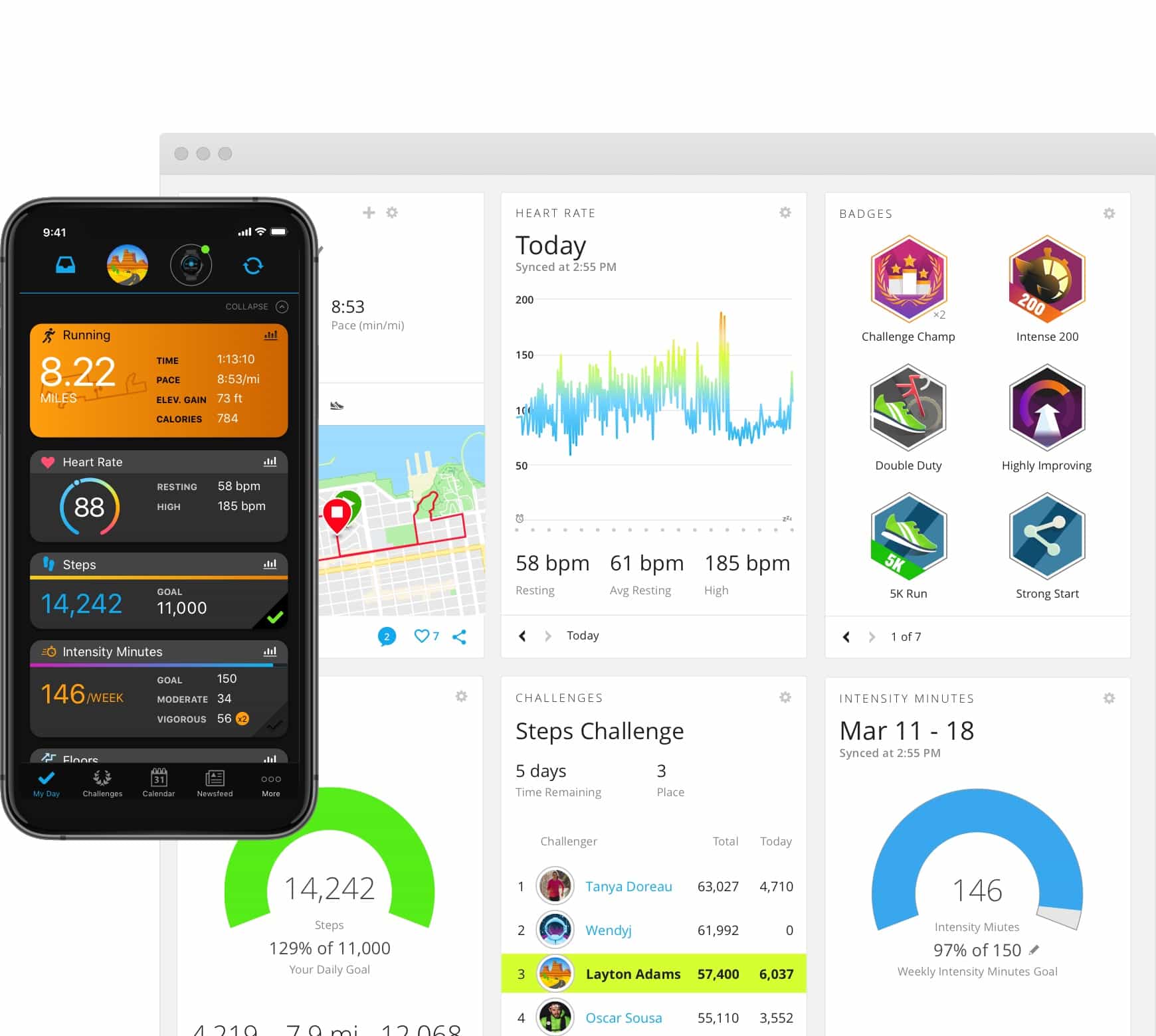
While navigating around Connect, it becomes immediately apparent that only a small section of the page needs to update each time — we’re not completely reloading everything. Connect is clearly able to request updates from some server and get back the information it needs. This is typical of modern websites, where there is a user interface (UI) web server that provides all the nice graphical pieces, and a separate back-end API server that provides the raw data to fill in the gaps.
If I can figure out how to talk to the API server without having to use the UI server, then I should be able to replicate this functionality in Python independent of a web browser entirely.
Behind the scenes
Connect’s JavaScript
From opening the developer tools in Chrome, it’s quite apparent that Connect uses technologies like webpack, babel and JSX with the React framework. Projects like this typically get compacted and ‘minified’ to reduce the size of the code the browser needs to load. However, this tends to make debugging nearly impossible as all comments are removed and functions get renamed and rearranged.
Fortunately for us, Connect also provides the ‘source maps’ that contain the file names and source code for the original project. We can attempt to reconstruct the project by processing these source maps using some basic Python code and writing files out to the hard disk.
If you’re interested in reading more about the technologies used to deliver JavaScript on the internet, the Mozilla Developer Network has an excellent writeup.
Chunks and source maps
Some research online lead me to believe that most projects of this sort only have a one compiled JavaScript file with one source map. However Connect has hundreds, split up into ‘chunks’ named like 5.6d2c3e3c.chunk.js or 152.43dceef1.chunk.js. This is an optimisation tactic used to make the page load faster for viewers, as the browser only needs to download the specific chunks it needs at any point in time and request additional ones later, rather than trying to get everything all at the very start.
To reconstruct the source code for the project, we need to be able to pull all of the chunks. This is complicated by the fact that they’re not named strictly numerically — there’s a hash code in there too. Thankfully, the base JavaScript file contains a dictionary of all of the chunks that we can use to download them ourselves. Once we have the list of chunks, downloading the source maps is just as easy — just stick .map at the end of the URL.
Recreating the sources
Getting the chunk list
I wrote some quick-and-dirty Python code to grab the main JavaScript file and pull out the list of chunk URLs.
import re, requests
BASE_URL = "https://connect.garmin.com/web-react/static/js/"
BUNDLE_URL = BASE_URL + "bundle.js"
def load_chunk_list():
response = requests.get(BUNDLE_URL)
chunk_map_re = re.search(r'c\.src=.+?{(0:".+?")}\[e]', response.text)
chunk_map = chunk_map_re.group(1).split(',')
chunk_list = []
for entry in chunk_map:
k, v = entry.split(":")
chunk_list.append('%s.%s.chunk.js' % (k, v[1:-1]))
return chunk_list
Downloading the source maps
From that list, we can then download the source map for each chunk:
def download_all_maps(chunk_list):
for chunk in chunk_list:
response = requests.get(BASE_URL + chunk + '.map')
with open('chunks/' + chunk, 'x') as f:
f.write(response.text)
Rehydrating the sources
Now that we’ve got the source map files, we can go through them to pull out the original code. A source map is a fairly basic JSON file containing an object with a few keys; we’re interested in sources and sourcesContent.
My code is pretty messy here so I’ll try and tidy it up for a future post, but the logic is essentially:
- Go through the
sourcesandsourcesContentarrays, element-by-element - Write the
sourcesContent[i]string to a file on the disk namedsources[i]
There is some manipulation I’m applying to the filename; this is mostly around the fact that some filenames are of the form webpack:///./node_modules/ui-connect/Notification/Notification.css?e097 which can’t make a valid filename.
Interesting finds
There’s a lot of interesting information here that we can search through, using a tool like grep or the ‘find in files’ feature of Sublime Text. Some of the more exciting bits I found were URLs for various API endpoints, as well as comments describing bugs found and fixed in the past.
Future devices and Connect features
I wrote this post a few days ago but held off on publishing it while I tidied up the code. Evidently I lost my opportunity to break the news because the Forerunner 945 and Menstrual Cycle Tracking features are now publicly announced.
There’s code and UI designs for what appears to be an unannounced new feature — Menstrual Cycle tracking. This must be nearly ready for release because it’s in the publicly-available version of Garmin Connect and is only protected by an ‘is this user a beta-tester’ flag. While this doesn’t directly impact me, it’s cool to see Garmin working on getting feature parity with something that Fitbit have had for some time.
There are also reference to a future device — The Forerunner 945 (called FR 945 in the code). Some research online shows that Garmin haven’t officially announced it yet, but it has been extensively leaked and estimates are pegging the reveal date as any time in the next few days.
Other stuff
There’s a lot of other interesting bits and pieces in here that I’ll try to take a look at in a future post, especially considering I haven’t even scratched the surface of interacting with the API yet.
Perhaps next time I’ll also spend less time on polish and look at getting the first mover advantage; it would be cool (even if somewhat vain) to see my blog cited as the source for a big feature announcement like this.
-
It is also possible to request an export of your Garmin account, but this is an all-or-nothing approach that can “take up to 30 days” to process. ↩